Building an AI Video Factory
June 2026
Inspiration
A week and a bit ago, June 6, I was going over the multimodal video virality predictor I helped make with Western AI during the school year. Honestly because of the combination of complexity and lack of patience (I just came back from Hong Kong, can you rlly blame me ) I was dozing off a lot.
I remembered those Stewie/Peter explainer videos trending last year but wanted to create my own but from scratch. All the while learning system design principles and how to really use Claude.
Initial Ideas
So what exactly is the user flow?
- Define a series: what the premise of the account, characters, personalities, voice ID(ElevenLabs), avatar(Image)
- Create a topic
- Topic research
- Script: grabbing context from the character and research generate a hook + dialogue.
- Script review
- Finding assets: that meant finding relevant GIFS (meme/reactionary) and Image(informational). Produce audio of script
- Render video: combining graphics and audio timings.
- Approval or rerender: approve or switch assets to remake video
- Autopost: connect social media platforms to autopost it to
Ended up skipping Autopost because after consulting Gemini ... didn't want to risk getting their accounts banned
Tech Stack
Next.js with database and smaller files on Supabase (Postgres). Background agent orchestration with Inngest: perplexity for up-to-date research, Claude scripting, Elevenlabs for voiceover and visuals via Giphy/Pexels.
Video rendering happens on Remotion with Lambda with the finished MP4 served from S3 + CloudFront. Auth is AWS Cognito, Upstash Redis for rate limiting.
All Typescript
The Backend
API layer
A lot of this part was mainly going back and forth with Supabase to make sure the data was inputted for the agents. Always checking who are you -> are you allowed to do this-> can you do this right now.
Auth
Cognito handles login and gives back a JWT. Before I directly made the token into a cookie from the client however realized if someone is able to inject JS they can directly grab the token. Therefore after client gets it from Cognito it would be sent to a server route that makes it an httpOnly cookie, so document.cookie can never see it.
// /api/auth/login (simplified)
app.post("/api/auth/login", async (req) => {
if (!req.headers["content-type"]?.includes("application/json")) return res.status(400)
const { accessToken } = req.body
await verifier.verify(accessToken) // throws if invalid
res.cookie("token", accessToken, { httpOnly: true, secure: true, sameSite: "lax" })
})
Note: the route rejects anything that isn't application/json. Without this, a text/plain request skips CORS entirely, allowing any website POST to login. This probably wasnt critical as there is already samesite and token verification but wasn't too hard to do, so why not.
From there, a proxy/middleware verifies cookies on every request.
DB
For supabase it was accessed two ways: an admin and regular client. The admin had full database access which was safe because it checked ownership (IDOR) for all the routes before any changes. The client was mainly used to fetch for status changes in the DB.
const { data } = await db.from("series")
.select("id").eq("id", seriesId).eq("user_id", userId).single()
if (!data) throw new NotFoundError()
Note: Row level security could handle this but because I used Cognito it needed additional work so I thought it would be more straightforward to do manual checks which was only a few more lines.
Agent Pipeline
Each agent is a separate Inngest function. They each own exactly one state transition (queued → researched → scripted → assets_ready → previewing). Once they entered a topic, it started.
Research
Perplexity's sonar-pro was used as it is search-grounded making sure the facts are relevant. the whole idea was to gather as many facts and specific details that the script could use.
Script
It had a 2 pass structure: stream raw text first (for the UI), then re-run for structuring in to JSON with schema (Zod)
// pass 1: stream for live UI feedback
const result = streamText({ model: anthropic("claude-sonnet-4-6"), system, prompt })
for await (const chunk of result.textStream) {
accumulated += chunk
if (Date.now() - lastSave > 300) await db.updateDraft(scriptId, accumulated) // delay writes
}
// pass 2: force text into a schema
const { output } = await generateText({
model: anthropic("claude-sonnet-4-6"),
output: Output.object({ schema: ScriptSchema }),
prompt: accumulated,
})
The prompt itself defined how many words per line, when to use each type of visuals (GIFS vs Images), including character personality and other rules.
Assets
For every line in the script that needs an asset it would grab with Giphy or Brave for visuals. ElevenLabs per line for voiceover using the speaking character's VoiceId.
An interesting problem was captions, I wanted it to be karaoke style meaning the word being spoken should have a different style. ElevenLabs returns timing per character, not per word, therefore we had to walk through the character array, accumulating letters until a space and save with the start + end timestamp.
// ElevenLabs gives per-character timing -> rebuild into words
for (const char of alignment.characters) {
if (char === " ") {
tokens.push({ text: currentWord, startMs, endMs })
currentWord = ""
} else currentWord += char
}
// result: [{ text: "hello", startMs: 0, endMs: 48 }, { text: "world", startMs: 72, endMs: 156 }]
Render Video
- Metadata
Remotion needs to know video length before rendering. Given the timeline driven by audio (voiceover length), each line's voiceover duration gets stacked end to end, producing a single lineTiming array that tells every layer (visuals, characters, captions) exactly when to appear and disappear.
{lineIndex, startFrame, durationFrames}
- Lambda Timeout problem + fix
Remotion renders videos by opening a headless browser on AWS Lambda, but it kept failing to load character images from Supabase within a 28-second timeout. The fix was to download the images beforehand and embed them as base64. No more fetching.
Note: this only applies to character images. GIFs/Images were directly from Giphy/Brave
- Video Composition The layout was simpler than I thought. Loop through line timing and show something for that line duration then disappear.
- Background video
- Visuals: each GIF/Image appear when line is spoken
- Characters: pop in with subtle bounce( sine wave + frame count)
- Captions: highlight word by word using the ElevenLabs timestamps from earlier
- Audio: play each voiceover clip during range
- Render and Poll
Lambda renders asynchronously so we just poll every 3 seconds to see if finished or failed.
const { renderId, bucketName } = await renderMediaOnLambda({
composition: "VideoComposition",
inputProps: { dialogue, visuals, audio, captions, characters: charactersWithDataUrls, backgroundUrl, backgroundDurationFrames },
codec: "h264",
})
while (true) {
const progress = await getRenderProgress({ renderId, bucketName, ... })
if (d)throw new Error(progress.errors[0]?.message)
if (progress.done) break
await sleep(3000)
}
The UI
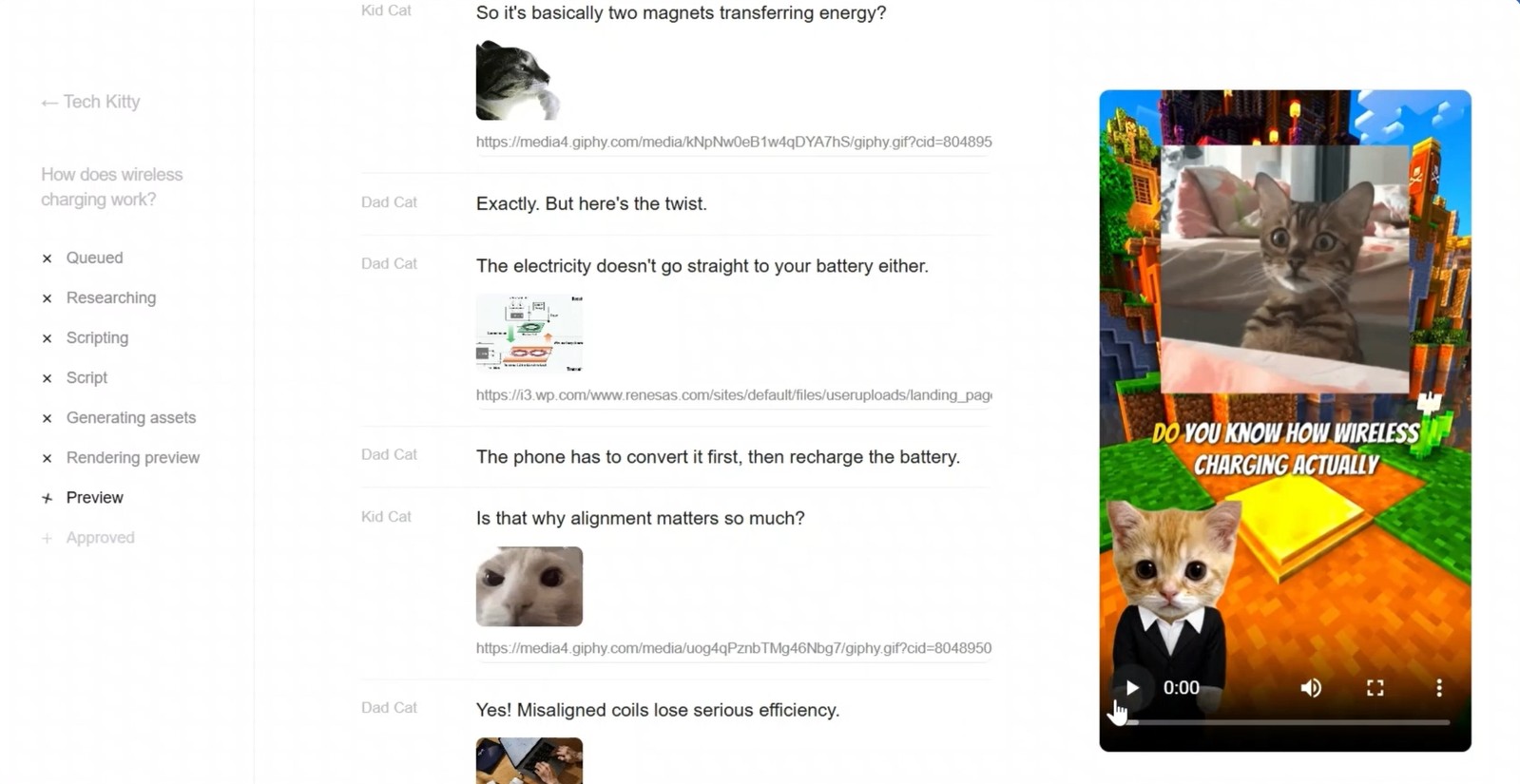
I kept it super simple cause the purpose and functionality were also very straightforward. dashboard (all your series) -> series page (topic queue and character info) -> topic editor (review script, watch preview, and customize)
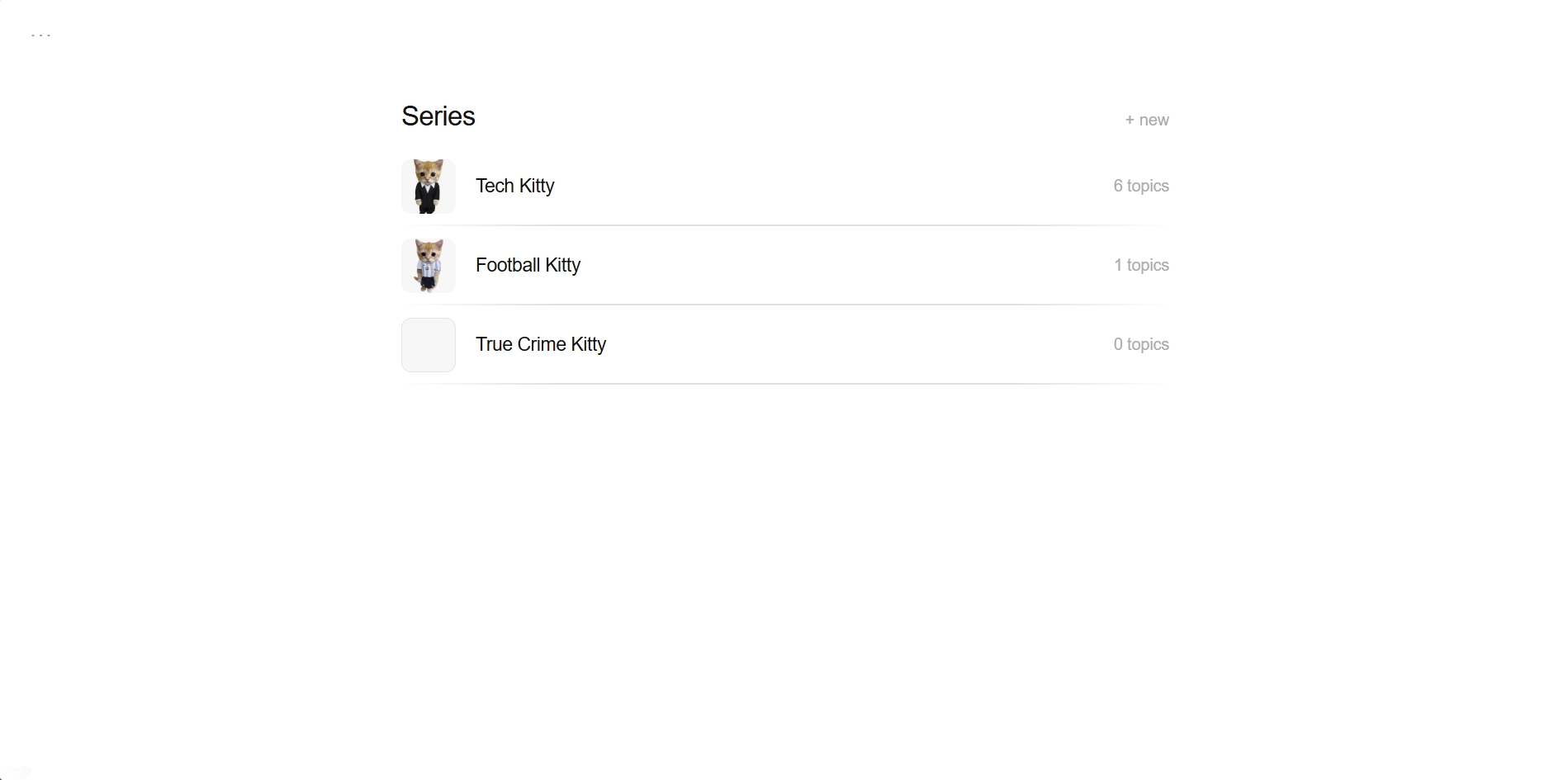
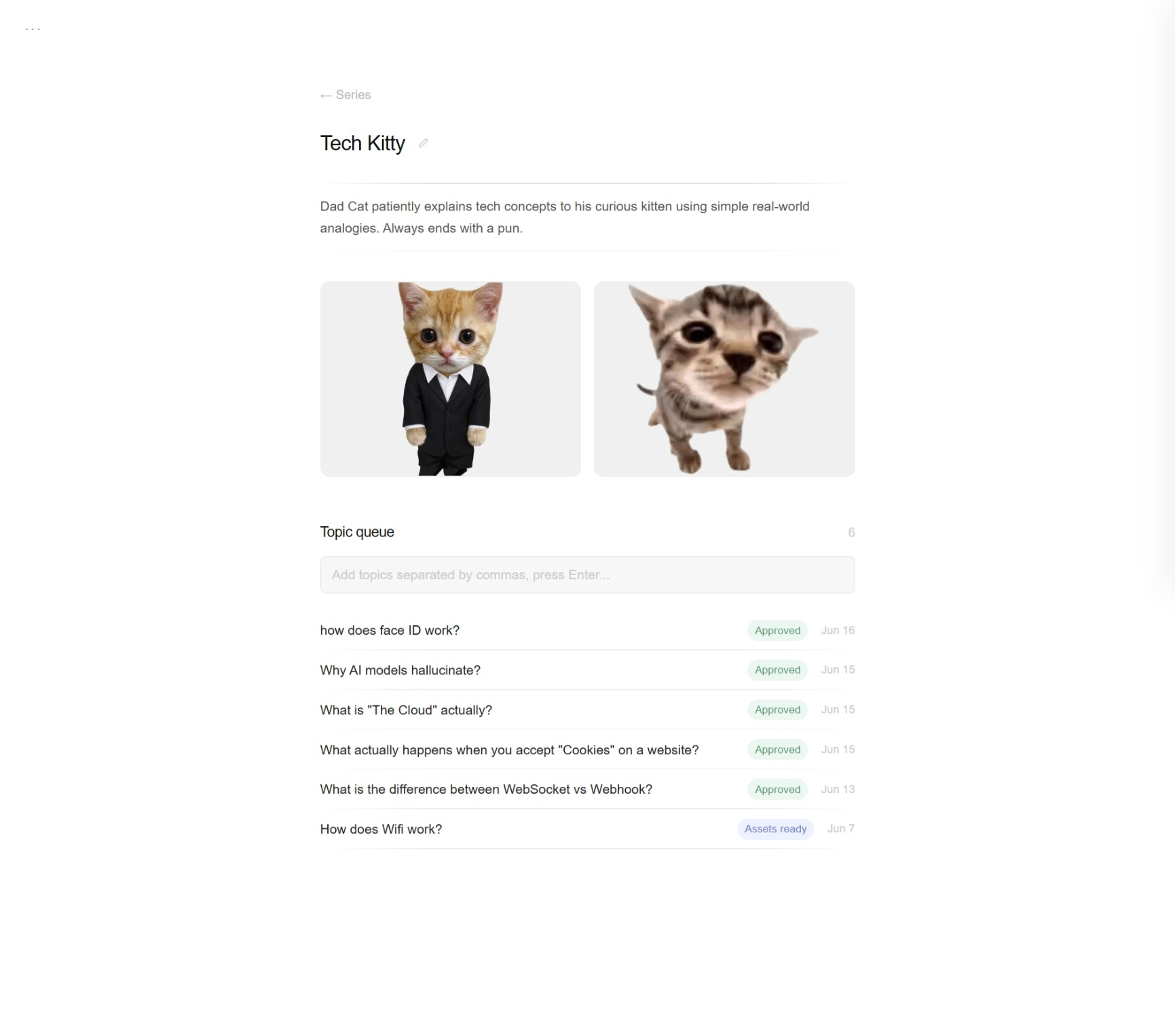
Topic Editor
I wanted it to be very clear when it required user input vs not. So I created 2 modes for this page.
In the passive state it just shows the status list except when the script was generating as it was streaming.

The moment the topic needed input, it flipped to an editor layout.
What I learned
This felt like my first big project in terms of caring about more than "does it work". Thinking about rate limiting, auth/security, and other infra stuff was more fun than I thought.
It also made me realize there were levels to this stuff. AWS alone is super deep with so many different tools. Also AI content, I'm averaging around 150 views, which makes sense as I haven't seen any Stewie/Peter videos recently. The algorithm is probably pushing for more authenticity and less "slop"; however I'll keep messing around to see if maybe adding sound effects or animation would help.
I definitely want to continue learning about AWS/infra, AI agents, Claude.
Check it out here-> makeitshorts.vercel.app
FOLLOW @kitty.tech_ on instagram!
